
Daten sind Basis für alle Formen der KI
"Fivetran Modern Data Stack Event Series" in München: Digitalisierung beginnt mit Daten
Für die immensen Datenmengen, die für Large Language Models (LLM) nötig sind, unterstützt Fivetran alle wichtigen Data-Lake-Destinationen
Von Thomas Hahnel, Geschäftsführer Lucy Turpin Communications
Über zwei Billionen US-Dollar beträgt die Marktkapitalisierung von Nvidia aktuell – so viel wie alle Unternehmen des DAX 40 zusammen. Diese Summe zeigt, welche immense Bedeutung der künstlichen Intelligenz zugeschrieben wird, für die Nvidia mit seinen Prozessoren die Hardware liefert. Ebenso wichtig für KI-Anwendungen sind jedoch die Daten. Hier haben viele Unternehmen noch mit großen Herausforderungen zu kämpfen. Wie sie diese bewältigen können, war Thema der Fivetran Modern Data Stack Event Series, die kürzlich in München stattfand. Personio und sennder berichteten aus der Praxis.
Daten sind Basis für alle Formen der KI. Diese sind meist ausreichend vorhanden – Unternehmen sammeln mehr Daten als je zuvor. Das Problem besteht darin, dass Daten aus verschiedenen Quellen verknüpft werden müssen, um Erkenntnisse zu liefern. Wie das gelingt, hat Mark Van De Wiel, Field CTO von Fivetran, als Weg zur Data Maturity mit vier Stufen beschrieben. Er startet mit der Situation, dass Daten gar nicht genutzt werden und Entscheidungen ausschließlich aufgrund von persönlichem Wissen und Erfahrung getroffen werden.
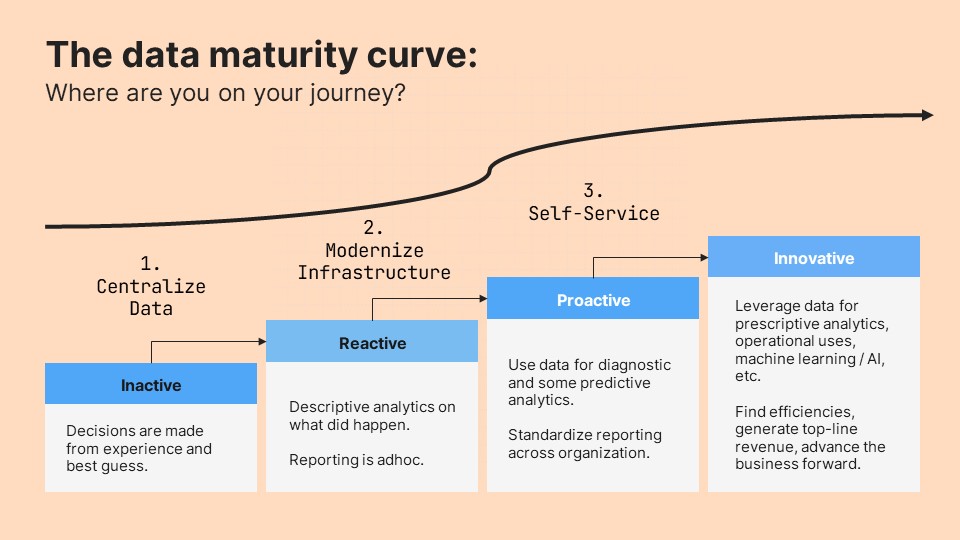
Auf die zweite Stufe gelangen Unternehmen, indem sie Daten aus verschiedenen Quellen verbinden können. Das gibt Ihnen die Möglichkeit, deskriptive Analysen und Ad-hoc-Reports zu erstellen. Das Problem: Jüngere Unternehmen erhalten oft unvollständige Analysen, etablierte haben mit einer Legacy- oder DIY-Infrastruktur zu kämpfen. "Hier scheitern zahlreiche Unternehmen", so die Erfahrung von Mark Van De Wiel. Denn die Zentralisierung von Daten ist eine komplexe Aufgabe: Der Aufbau und die Pflege von Datenpipelines sind zeit- und ressourcen-intensiv, die Pipelines meist von Unterbrechungen gekennzeichnet. Das führt zu langsamen Prozessen und einer mangelhaften Datenqualität, die sich nicht als Basis für vertrauenswürdige KI-Anwendungen eignet.
Nutzung moderner Technologien erfordert moderne Infrastruktur
Eine moderne Infrastruktur kann diese Probleme lösen und Unternehmen auf die dritte Stufe bringen. Hierfür hat sich der Modern Data Stack (MDS) etabliert. Diese Kombination aus Tools besteht in der Regel aus
• >> Datenpipelines, um Daten aus verschiedenen Quellen auf eine zentrale Datenplattform zu bringen,
• >> einem Data Warehouse oder Data Lake als zentrale Datenplattform,
• >> einem Datentransformationstool zur Aufbereitung der Rohdaten,
• >> einer Datenvisualisierungs- oder Business-Intelligence- (BI) Plattform zur Datenanalyse.

"Weil sie alle auf Standards basieren, etwa SQL, und die Tool-Anbieter eng zusammenarbeiten und ein Ökosystem bilden, integrieren sich die Tools wirklich gut", so Van De Wiel. "Mit seiner vollständig verwalteten, automatisierten Data Movement Plattform ist auch Fivetran Teil des Modern Data Stack. Unsere Plattform ermöglicht Unternehmen, Daten aus verschiedenen Quellen zu zentralisieren – und zwar hochzuverlässig, sicher, effizient und schnell." Für die immensen Datenmengen, die für Large Language Models (LLM) nötig sind, unterstützt Fivetran alle wichtigen Data-Lake-Destinationen. Durch die RAG- (Retrieval Augmented Generation) Architektur kann die Lösung Generative-KI-Modelle um die erforderlichen Daten ergänzen.

Unternehmen verfügen auf dieser dritten Stufe also über Daten mit hoher Qualität, bei Bedarf in Echtzeit. Damit haben sie Basis geschaffen nicht nur für detaillierte Auswertungen und Predictive Analytics sowie unternehmensweit standardisierte Reports, sondern auch für KI, ML und LLM.
"Es gibt noch eine vierte Stufe, weil Unternehmen jetzt dafür sorgen müssen, diesen Status trotz Veränderungen seitens der Datenquellen, der Nutzer oder des Unternehmens zu erhalten und zu skalieren – und zwar so, dass die Datenteams nicht zu viel Zeit dafür aufwenden müssen, die dann für wertschöpfende Tätigkeiten fehlt", erklärt Van De Wiel. Als Lösung beschreibt er zwei Maßnahmen: erstens durch Self-Service-Datenzugriff für die Mitarbeitenden das Datenteam entlasten, und zweitens die technologisch versierten Mitarbeitenden mit den nötigen Tools auszustatten, sodass sie ihre Datenbewegungen in den eigenen Datenbanken innerhalb des Modern Data Stack selbst verwalten können. Das ist möglich, weil in einem modernen Data Warehouse oder Data Lake die Datenverarbeitung und -speicherung getrennt sind.
Hier angekommen können Unternehmen wirklich innovativ sein. Sie können Daten nutzen, um den Markt und das Unternehmen zu verstehen und mit Hilfe modernster Technologien neue Möglichkeiten zu schaffen. Die Ergebnisse: Steigerung der Effizienz, Entwicklung leistungsfähiger neuer Produkte und das Erzielen von Umsatzerlösen aus Datenprodukten und der Weiterentwicklung des Unternehmens.
Praxisbeispiel Morgan Stanley
Ein Unternehmen, das bereits alle vier Stufen zur Data Maturity genommen hat, ist Morgan Stanley. Der Fivetran-Kunde hat seine Datensilos aufgebrochen, ist in die Cloud migriert und hat eine neue Datenarchitektur mit Fokus auf Datenzugriff und Echtzeitdaten aufgesetzt. Damit wuchs die Gruppe der internen Datennutzer innerhalb von vier Jahren von ca. 100 auf rund 2.000. Auf Basis von KI und Machine Learning kann das Unternehmen jetzt innovative Lösungen schaffen. Zum Beispiel nutzen die Finanzberater keinen marktorientierten Ansatz mehr, sondern können mit einem individuellen Ansatz die besten Empfehlungen für jeden einzelnen Kunden ermitteln – ein großer Wettbewerbsvorteil.
Der Digitalisierungsweg von Personio und sennder
Personio, europaweit führende HR-Software für KMU, und sennder, Europas führende Spedition, berichteten auf dem Fivetran Modern Data Stack Event von ihrem Weg zum datenbasierten Unternehmen. Dieser begann ebenfalls mit der Zentralisierung der Daten.
Personio setzte anfangs auf selbstentwickelte Tools auf Basis von AWS-Services und APIs. Weil sich vor allem die APIs sehr oft ändern, war das Datenteam stark damit beschäftigt, die Tools aktuell zu halten. Dadurch blieb kaum Zeit, um aus den Daten einen Mehrwert für das Unternehmen zu schaffen.
sennder startete mit einem kundenspezifischen Airflow-Setup, mit dem Daten aus zwei Quellen in eine Postgres Datenbank geladen wurden. Auch hier verbrachte der Data Engineer den Großteil seiner Zeit mit Maintenance-Aufgaben. Als sennder sein erstes exponentielles Wachstum erlebte, zeigt sich ein weiterer, großer Nachteil: Die Datenbank war nicht skalierbar. Deshalb entschied sich die digitale Spedition dafür, einen Modern Data Stack aufzubauen. Diese besteht aus Snowflake als Daten-Plattform, Fivetran als Data Movement Platform, dbt für die Datentransformation und Looker als BI-Tool.
Heute kann sich das sennder-Datenteam auf die Aufgaben konzentrieren, die das Unternehmen voranbringen. Jeder Mitarbeitende hat Zugriff auf die für ihn relevanten Daten und kann im Self-Service BI-Dashboards erstellen, um datengestützte Entscheidungen zu treffen. Darüber hinaus nutzt sennder die Daten für das Training von ML-Modellen und die Entwicklung datengestützter Produkte.

Technologie ist nicht alles
Auf einen weiteren entscheidenden Aspekt machte Raffael Dzikowski, Staff Data Platform Engineer bei Personio, aufmerksam: "Man kann die beste Plattform der Welt mit tollen Features aufbauen. Aber wenn sie für die Nutzer zu kompliziert ist, wird es kein Erfolg." Das Thema griff auch Edwin Commandeur, Principal Field Product Manager bei Fivetran, in seinem Vortrag auf. Er empfahl dringend, verpflichtende Schulungen durchzuführen, damit alle in der Organisation die Daten verstehen und wissen, wie sie sie für ihre spezifischen Anwendungsfälle effektiv nutzen können. Auch das Thema Sicherheit müsse Bestandteil der Schulungen sein.
Weitere Erfolgsfaktoren sind laut Commandeur die nötigen technischen und personellen Ressourcen sowie Prozesse, die auf die Nutzung des Modern Data Stack angepasst sind. "Als wichtigsten und gleichzeitig schwierigsten Punkt sehe ich jedoch, die gemeinsame Nutzung von Daten durchzusetzen", ergänzt Commandeur. "Ich finde es nachvollziehbar, dass viele Teams ihre Daten nur ungern zur Verfügung stellen. Doch für eine umfassende Datennutzung mit solidem Erkenntnisgewinn führt kein Weg daran vorbei. Ein Fivetran-Kunde hat das gelöst, indem er die Daten klassifiziert und Regeln formuliert hat, wie sie genutzt werden dürfen."
Personio hat diese Notwendigkeit auch erkannt und zahlreiche Trainings durchgeführt, um alle Mitarbeitenden in dem Prozess mitzunehmen und ein Mindset zu etablieren, in dem Daten als wertvolle Ressource begriffen werden. Auf der technologischen Ebene hat sich Personio für Fivetran entschieden. "Damit konnten wir unsere Quellen sehr einfach in Minutenschnelle anbinden", erinnert sich Raffael Dzikowski. "Die Datenpipelines sind robust und stabil, sodass wir die Gewissheit haben, immer korrekte, aktuelle Daten zu nutzen, auch Echtzeitdaten, wo das nötig ist. Und unser Datenteam hat jetzt auch die Zeit, um damit Innovationen zu schaffen." (Fivetran: ra)
eingetragen: 14.05.24
Newsletterlauf: 15.07.24
Fivetran: Kontakt und Steckbrief
Fivetran automatisiert alle Arten von Data Movement im Zusammenhang mit Cloud-Datenplattformen. Das gilt vor allem für die zeitaufwendigsten Teile des ELT-Prozesses (Extract, Load, Transform) - von der Extraktion von Daten über das Handling von Schema-Drifts bis hin zu Daten-Transformationen. Damit können sich Data Engineers auf wichtigere Projekte konzentrieren, ohne sich um die Data Pipelines kümmern zu müssen. Mit einer Up-Time von 99,9 Prozent und sich selbst reparierenden Pipelines ermöglicht Fivetran Hunderten von führenden Marken weltweit, darunter Autodesk, Lionsgate und Morgan Stanley, datengestützte Entscheidungen zu treffen und so ihr Unternehmenswachstum voranzutreiben. Fivetran hat seinen Hauptsitz in Oakland, Kalifornien, und verfügt über Niederlassungen auf der ganzen Welt.
Der deutschsprachige Markt wird aus dem Büro in München betreut. Zu den Kunden in Deutschland zählen DOUGLAS, Hermes, Lufthansa, Siemens, VW Financial Services und Westwing. Weitere Informationen unter www.fivetran.com.
Kontaktdaten
Fivetran Germany GmbH
Franz-Joseph-Str. 11
80801 München
E-Mail: hallo[at]fivetran.com
Webseite: https://fivetran.com/de
Dieses Boilerplate ist eine Anzeige der Firma Fivetran.
Sie zeichnet auch für den Inhalt verantwortlich.
Lesen Sie mehr:
Automatisierte Datenintegration
Risiken für Produktionssysteme eliminiert
Fivetran und dbt Labs fusionieren
Verantwortung für Datenschutz und Compliance
Modernisierung der Dateninfrastruktur
Datentransformation transparenter zu gestalten
Datengrundlagen für Analysen und KI
Fivetran präsentiert erweitertes "Connector SDK"
Compliance als größte Herausforderung
Fivetran: Monica Ohara mit umfassender Erfahrung
Fivetran: Vereinbarung zur Übernahme von Census
Managed Data Lake Service auf Microsoft Azure
KI erfordert riesige Mengen hochwertiger Daten
Datenintegration für Unternehmen jeder Größe
Fivetran vereinfacht Datenintegration
Nahtlose Replikation großer Datensätze
Die Datenkultur hat sich grundlegend gewandelt
Data Governance und Datensicherheit
Fivetran weiter auf der Erfolgsspur
Cloud-Deployment für Fivetran-Plattform
Fivetran erweitert Partnerschaft mit Snowflake
Datenautobahn ohne Stau für die Logistik
Nutzung von KI- und Generative-KI-Technologien
Data Lake Management automatisiert und vereinfacht
Daten sind Basis für alle Formen der KI
Schlechte Datenpraktiken noch weit verbreitet
Datenbasierte Entscheidungen treffen
Datenaustausch im Unternehmen automatisieren
Reduzierte Latenzzeiten und Kosten
25 Jahre Erfahrung im SaaS-Umfeld
Fivetran sorgt für Business Insights
Kontrollierte, benutzerfreundliche Repositories
Aufbau einer soliden Data-Lake-Grundlage
Cloud Data Lake, Lakehouse oder Warehouse
Skalierbare Konnektoren und Destinationen
Fivetran als Launch-Partnerin
Prozess zur Datenintegration in BigQuery
Weniger Kosten für Neukundengewinnung
Inspirierende Führungspersönlichkeit
Anbindung an praktisch jede SaaS-Anwendung
Unterstützung von Amazon S3
Fivetran setzt Wachstum fort
Daten in Cloud- & On-Premise-Umgebungen
Fivetran: Führungsteam ausgebaut
Data Act könnte schon 2024 in Kraft treten
Mit Cloud-Architektur zum "Master of Data"
Vorteile automatisierter Datenintegration
Schwierigkeiten bei der Bereitstellung der Daten
Verantwortung für Datenschutz und Compliance
Starke Dateninfrastruktur muss Priorität werden
Datengrundlagen für Analysen und KI
Fivetran präsentiert erweitertes "Connector SDK"
Compliance als größte Herausforderung
Fivetran: Monica Ohara mit umfassender Erfahrung
Fivetran: Vereinbarung zur Übernahme von Census
Managed Data Lake Service auf Microsoft Azure
KI erfordert riesige Mengen hochwertiger Daten
Datenintegration für Unternehmen jeder Größe
Fivetran vereinfacht Datenintegration
Nahtlose Replikation großer Datensätze
Die Datenkultur hat sich grundlegend gewandelt
Data Governance und Datensicherheit
Fivetran weiter auf der Erfolgsspur
Cloud-Deployment für Fivetran-Plattform
Fivetran erweitert Partnerschaft mit Snowflake
Datenautobahn ohne Stau für die Logistik
Nutzung von KI- und Generative-KI-Technologien
Data Lake Management automatisiert und vereinfacht
Daten sind Basis für alle Formen der KI
Schlechte Datenpraktiken noch weit verbreitet
Datenbasierte Entscheidungen treffen
Datenaustausch im Unternehmen automatisieren
Reduzierte Latenzzeiten und Kosten
25 Jahre Erfahrung im SaaS-Umfeld
Fivetran sorgt für Business Insights
Kontrollierte, benutzerfreundliche Repositories
Aufbau einer soliden Data-Lake-Grundlage
Cloud Data Lake, Lakehouse oder Warehouse
Skalierbare Konnektoren und Destinationen
Fivetran als Launch-Partnerin
Prozess zur Datenintegration in BigQuery
Weniger Kosten für Neukundengewinnung
Inspirierende Führungspersönlichkeit
Anbindung an praktisch jede SaaS-Anwendung
Unterstützung von Amazon S3
Fivetran setzt Wachstum fort
Daten in Cloud- & On-Premise-Umgebungen
Fivetran: Führungsteam ausgebaut
Data Act könnte schon 2024 in Kraft treten
Mit Cloud-Architektur zum "Master of Data"
Vorteile automatisierter Datenintegration
Schwierigkeiten bei der Bereitstellung der Daten